Table of Contents
Those bench start with the inject / httpterm configuration from direct benches, with 270-290k connections/s between a client and a server.
Monitoring graphs for the different benches can be found here.
Gateway
A gateway should be as neutral as possible on the network trafic going through it. If we can get 270k hits by having client and server talking directly, it would be nice to also have that while it transit via our gateway.
Having 6 servers, the most we can do is probably having 2 clients hitting on 3 servers.
Baseline
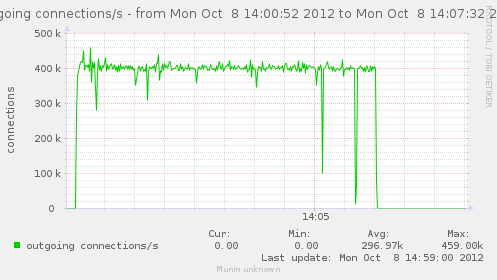
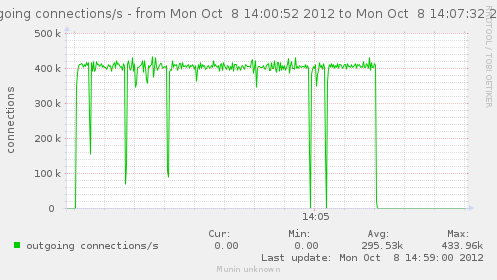
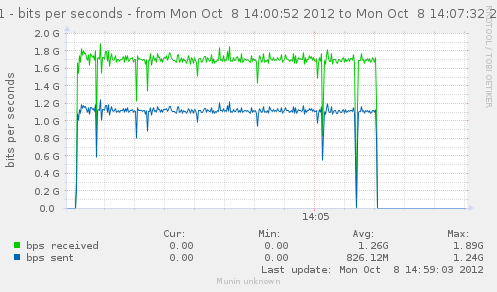
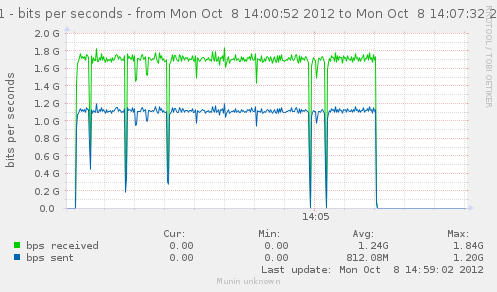
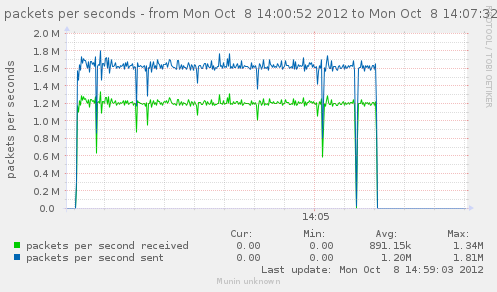
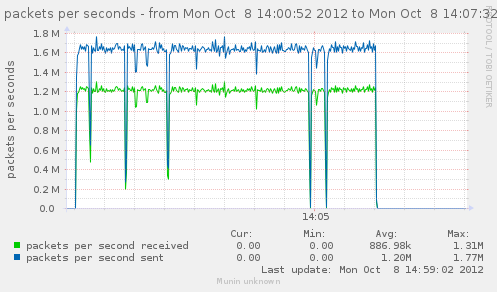
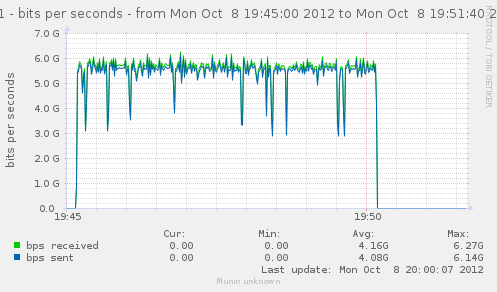
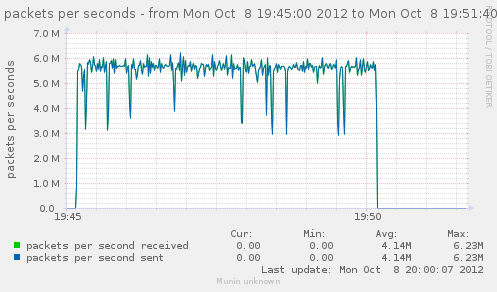
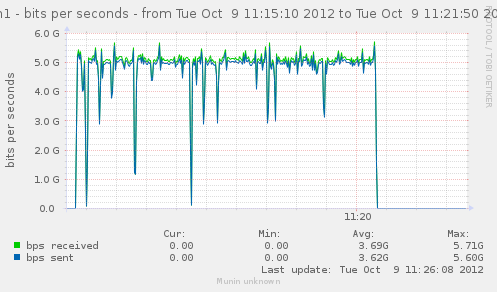
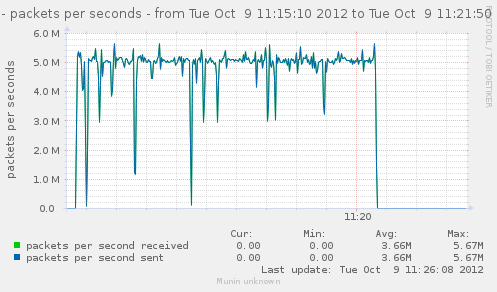
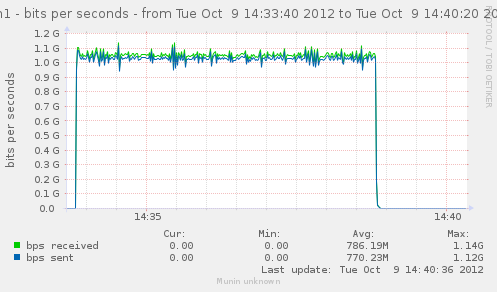
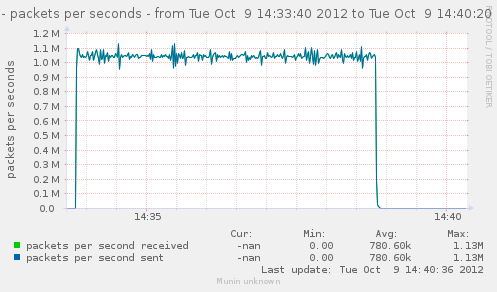
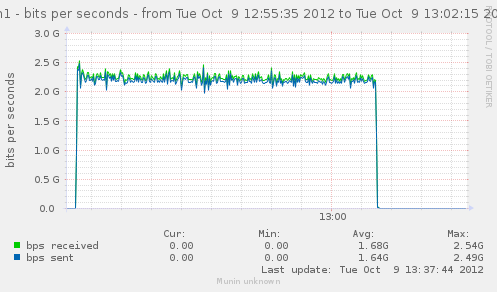
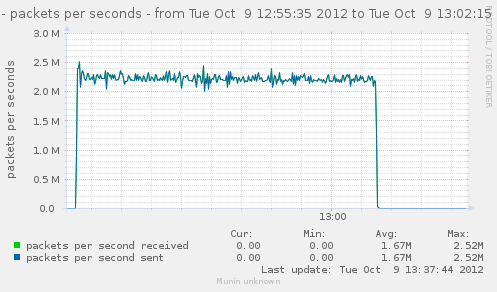
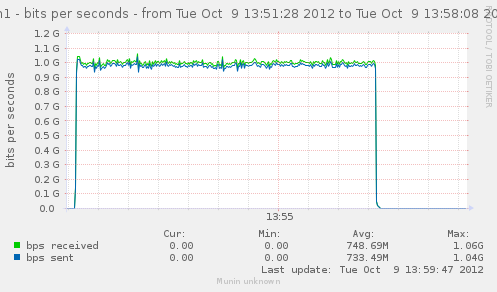
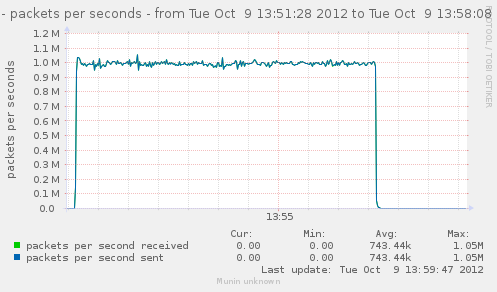
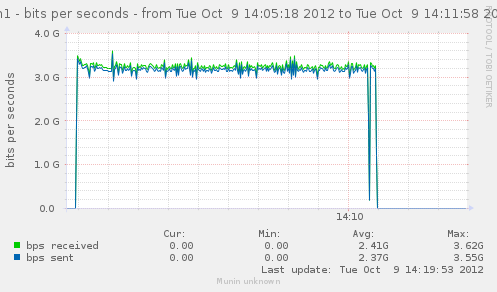
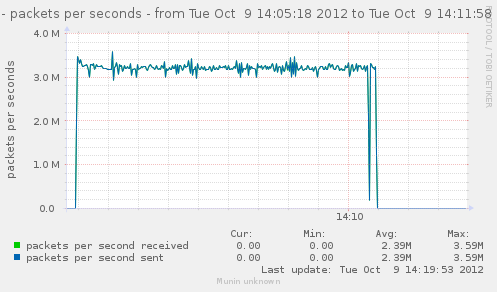
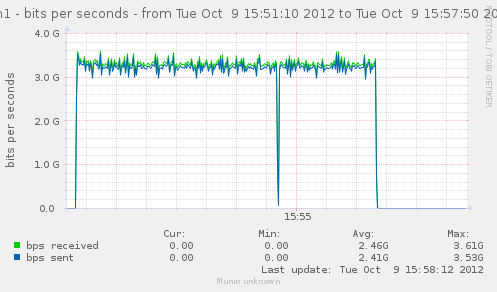
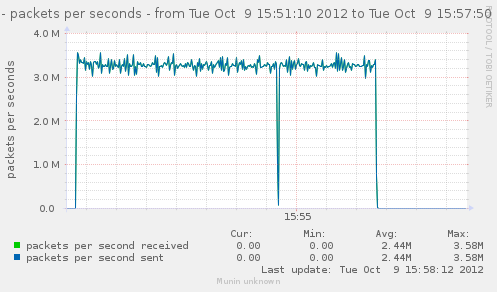
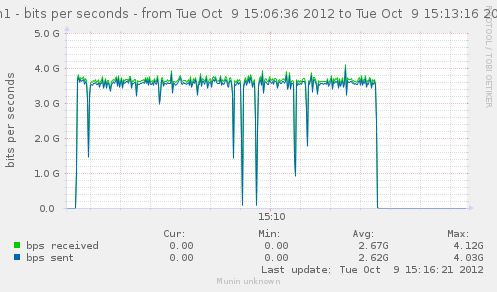
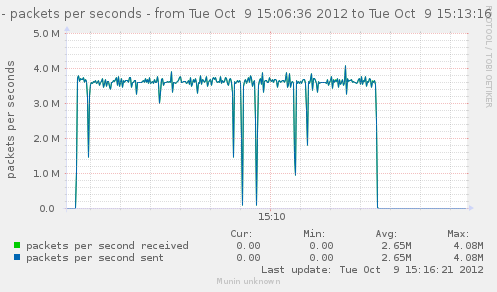
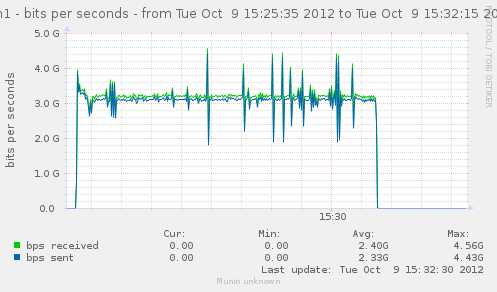
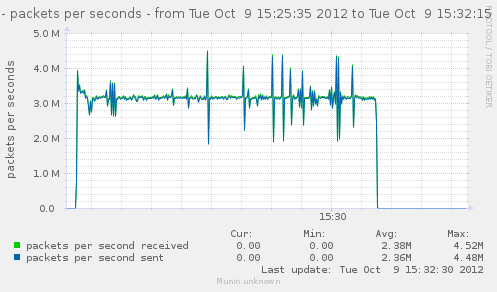
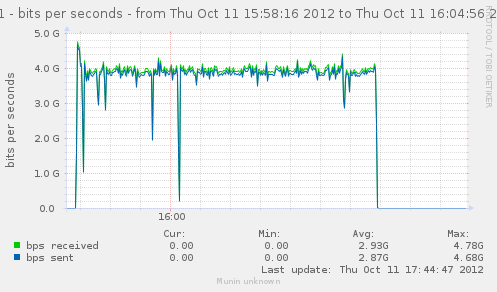
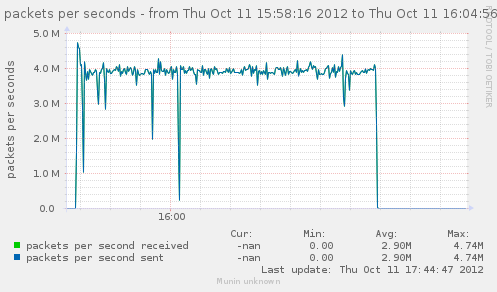
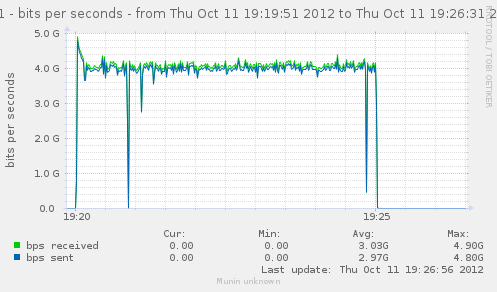
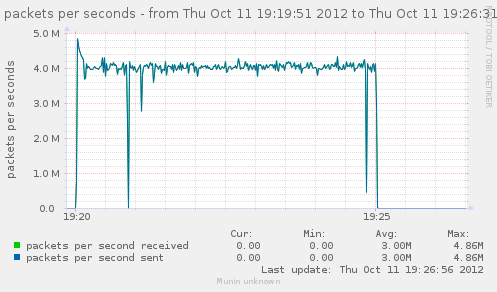
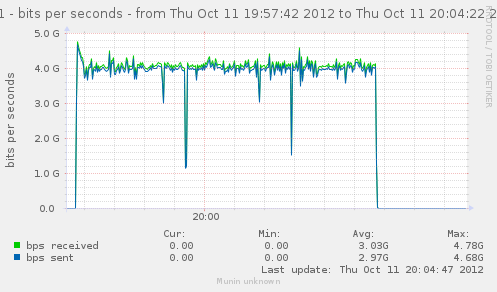
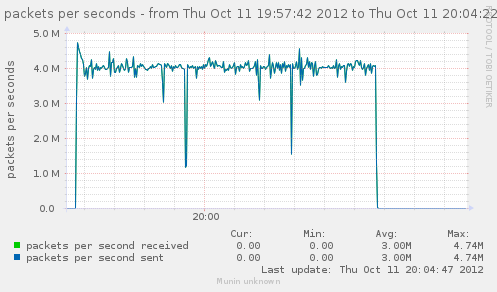
For a first baseline, we start with 2 clients hitting 3 servers, directly. No gateway involved.
If we check the different graph to get an idea of the trafic going on, we have (approximate reading on graphs) :
| what | per client | per server | total | graph |
|---|---|---|---|---|
| conn/s | 400k | 266k | 800k | cli1 cli2 |
| Gbps from cli/srv | 1.1/1.7 | 0.75/1.12 | 2.4/3.4 | cli1 cli2 |
| Mpkt/s from cli/srv | 1.2/1.62 | 0.8/1.08 | 2.4/3.24 | cli1 cli2 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Well, we can have about a little over 3Gbps, with 800k connections/s. That might not be enough to reach the limit of a 10Gbps gateway, but it should already be enough to give us a hint of some limits.
Gateway
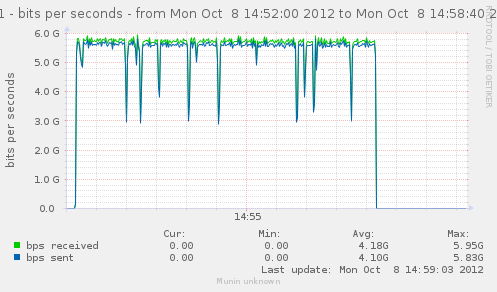
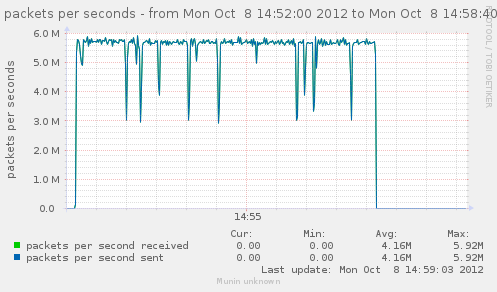
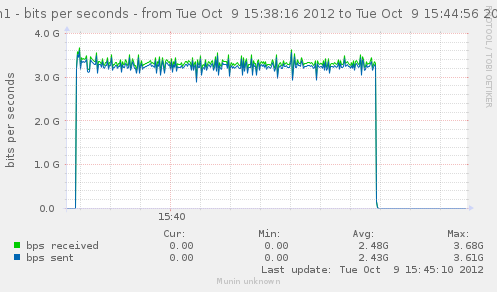
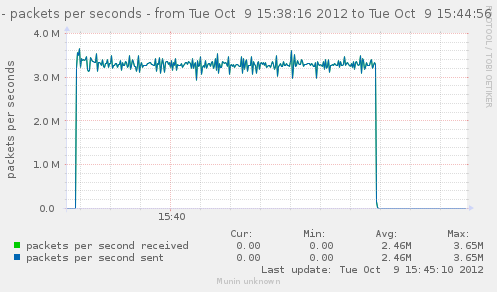
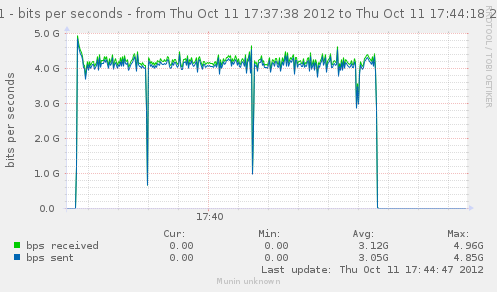
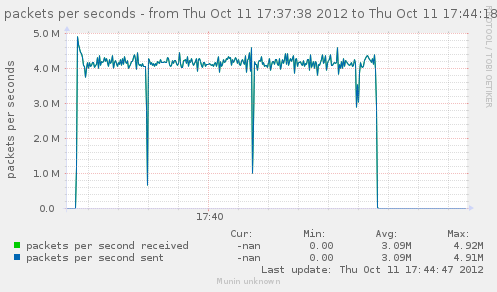
Now that we have an idea of the trafic we can generate, lets see how it gets handled by a single gateway.
For our first test, the gateway will use the same interface in and out. That should theoricaly give us 5.6Gbps in and out of it.
We make sure our gateway forward the packets, and doesn't send any redirect (I use the same subnet, so default might send redirect to avoid using the useless gateway).
gateway#sysctl.conf net.ipv4.ip_forward = 1 net.ipv4.conf.all.accept_redirects = 0 net.ipv4.conf.all.send_redirects = 0 net.ipv4.conf.default.accept_redirects = 0 net.ipv4.conf.default.send_redirects = 0 net.ipv4.conf.eth0.accept_redirects = 0 net.ipv4.conf.eth0.send_redirects = 0 net.ipv4.conf.eth1.accept_redirects = 0 net.ipv4.conf.eth1.send_redirects = 0
And something “heard” as being a good idea (checked in later bench) :
gateway#/etc/rc.local ethtool -G eth1 rx 4096 ethtool -G eth1 tx 4096
As we don't have any process that will be running here, and only the kernel handling the interupts, the irq affinity is spread among all the processor threads :
eth1-TxRx-0 0 eth1-TxRx-1 1 eth1-TxRx-2 2 [...] eth1-TxRx-22 22 eth1-TxRx-23 23
Results seems to indicate something very near the total of in/out we had earlier, which is explained by the fact both go in and out of our gateway via the same interface.
{kind=link}
{kind=link}
no rules
Ok, without doing anything but forwarding the trafic, it gets pretty nicely. Lets just check it doesn't change anything if we have the firewall up, but without any rules.
iptables -L iptables -t mangle -L iptables -t raw -L
With no rule, and the 3 tables filter, raw and mangle, we already get down from 5.7 to 4.9 (both, Gbps and M pkt/s). That's down from 800k to just under 700k conn/s.
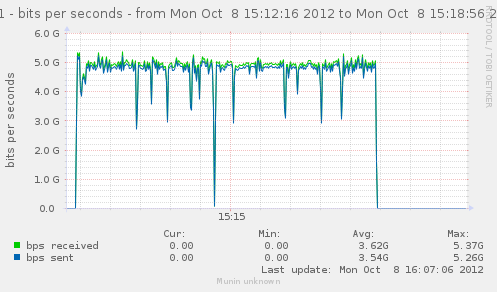{kind=link}
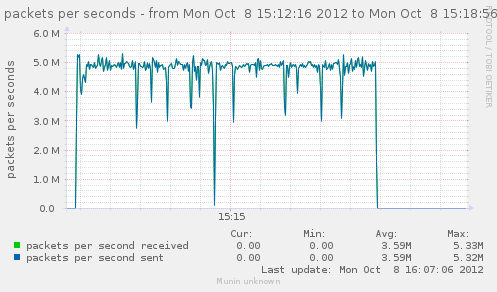{kind=link}
Firewall
Conntrack
Anyone that already used conntrack on a system having alot of connections noticed the default limits of connections tracking. If we want to handle hundreds of connections, we have to increase the default values.
# nat iptables -t nat -L # load the conntrack modules (ipv4) iptables -I FORWARD -m state --state ESTABLISHED iptables -D FORWARD -m state --state ESTABLISHED # increase the max conntrack (default: 256k) echo 33554432 > /proc/sys/net/netfilter/nf_conntrack_max # increase the conntrack hash table size - default: 16k echo 33554432 > /sys/module/nf_conntrack/parameters/hashsize
That will give us some conntrack informations. Lets see what impact it has on our connection rate.
average connection rate over 5 minutes : 150976
But looking at the graph, we see a breakdown. It starts at 180k for 120 seconds, then there is a drastic drop to an average of 135k for the rest of the time.
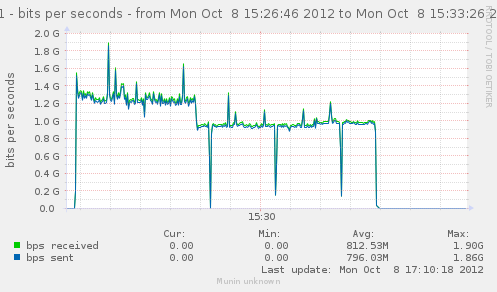{kind=link}
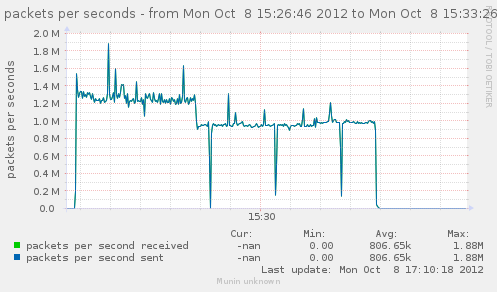{kind=link}
As the conntrack count increase in a linear form, up to about 21.2M, and decrease from that time, it seems to drop when the first timeout start to hit.
Having conntracking gives a performance hit. Having tracking timeouts while gives an other performance hit.
To make sure it is related, we checked what timeouts were at 120, and changed them.
cd /proc/sys/net/netfilter grep 120 /proc/sys/net/netfilter/* nf_conntrack_tcp_timeout_fin_wait:120 nf_conntrack_tcp_timeout_syn_sent:120 nf_conntrack_tcp_timeout_time_wait:120 echo 150 > nf_conntrack_tcp_timeout_fin_wait echo 180 > nf_conntrack_tcp_timeout_syn_sent echo 60 > nf_conntrack_tcp_timeout_time_wait
Testing with those values allowed us to get the break at 60 seconds. Connections gets in time_wait, and expires after 60s instead of 120s.
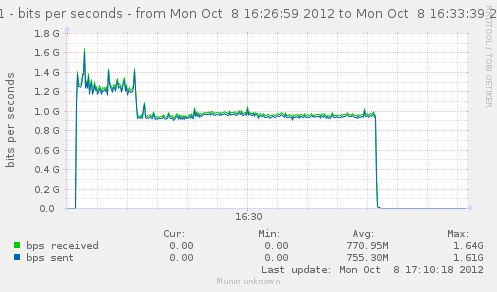{kind=link}
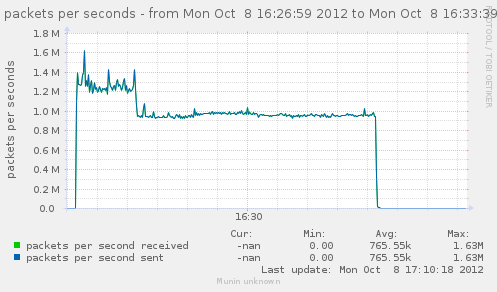{kind=link}
Testing with nf_conntrack_tcp_timeout_time_wait set to 1s gives directly the low performances, even if the conntrack stay under 200k, instead of a few millions.
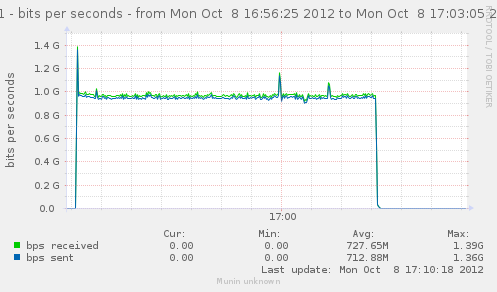{kind=link}
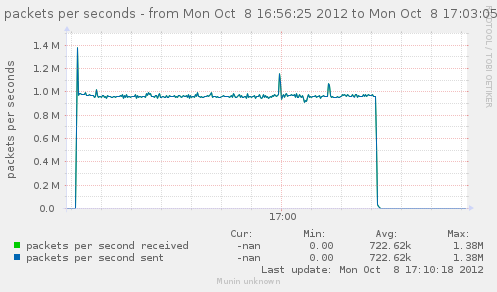{kind=link}
For our heavy connections, we clearly need to be able to *not* track them.
notrack
Obviously, not tracking those requests would probably be a good idea. Lets add the rules to just do that, and see if it helps.
- raw
- A PREROUTING -d 10.128.0.0/16 -p tcp -m tcp –dport 80 -j NOTRACK
- A PREROUTING -s 10.128.0.0/16 -p tcp -m tcp –sport 80 -j NOTRACK
- A PREROUTING -d 10.132.0.0/16 -p tcp -m tcp –dport 80 -j NOTRACK
- A PREROUTING -s 10.132.0.0/16 -p tcp -m tcp –sport 80 -j NOTRACK
- A PREROUTING -d 10.148.0.0/16 -p tcp -m tcp –dport 80 -j NOTRACK
- A PREROUTING -s 10.148.0.0/16 -p tcp -m tcp –sport 80 -j NOTRACK
That let us get about the same results as without the firewall modules loaded. CPU usage on the firewall seems to be lightly more on the 2 thread that handles most of the interrupts. (I'd say from about 15-17% to 18-20%)
Here, one of the CPU is used at 100%, with only about 4.1G bps, 4.2M pkt/s, total of about 590k conn/s instead of our 800k without firewall.
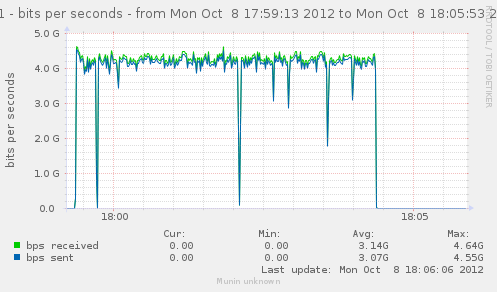{kind=link}
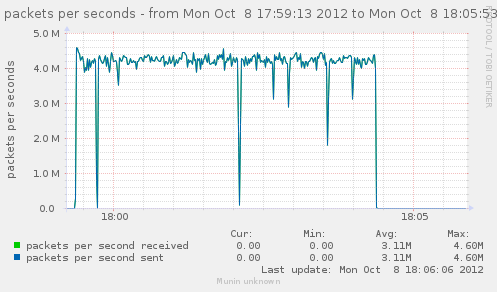{kind=link}
Trying to get only one rule for notrack get un slightly better performances :
- raw
- A PREROUTING -j NOTRACK
That give us about 620k conn/s.
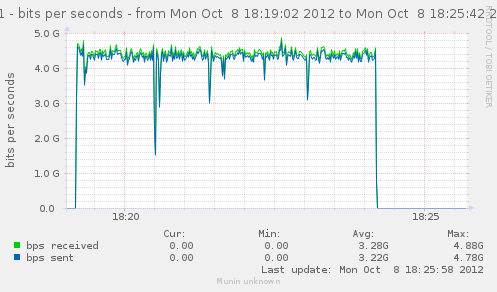{kind=link}
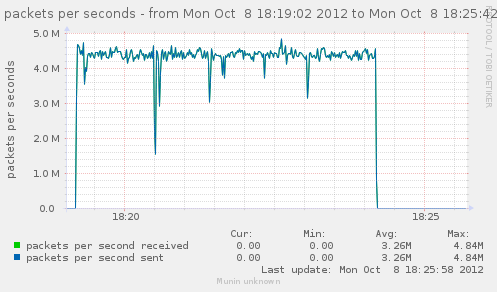{kind=link}
simple rules
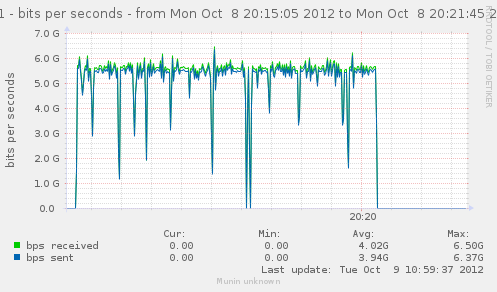
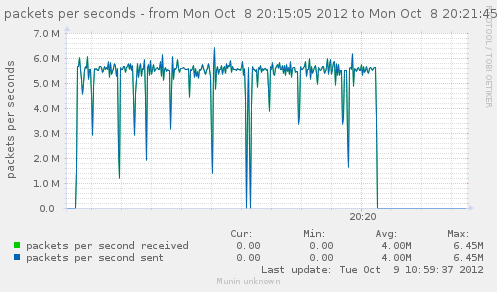
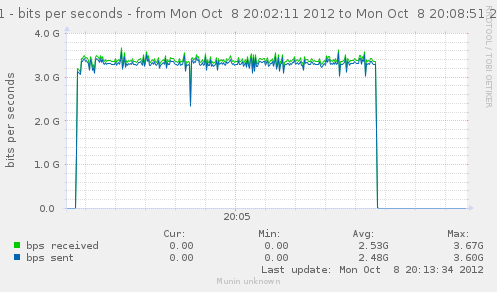
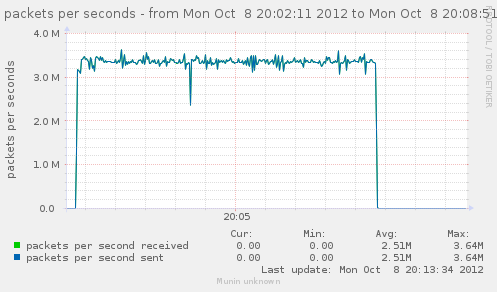
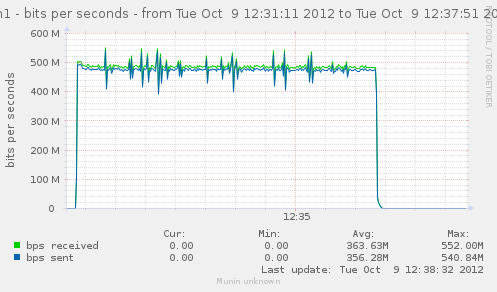
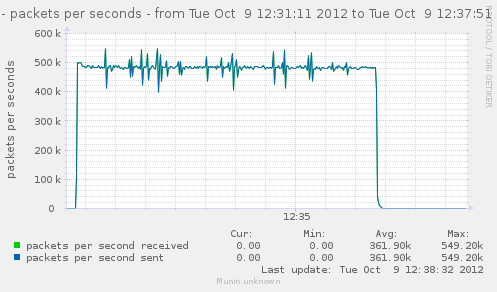
Lets get back to a configuration without nat loaded, and see how a few matching rules can affect our CPU usage, and decrease the rate we have.
Earlier, we tried with directly filter, raw and mangle.
Lets try with just filter loaded, and no rules, and then try adding useless matches, like checking source IP with IP we are not even considering.
# with n being the matching rules...
n=64
iptables -F ; for ((i=0;i<n;++i)) ; { iptables -A FORWARD -s 10.0.0.$i ; }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
other matches
Source match has an impact on the requests. Lets check other kind of match.
Tests done with 256 match rules.
| match rule | conn/s | pkt/s | graph |
|---|---|---|---|
| -m u32 –u32 ““0xc&0xffffffff=0xa0000`printf %02x $i`” | 67k | 480k | bps pkt |
| -p udp -m udp –dport 53 | 315k | 2.4M | bps pkt |
| -p tcp -m tcp –dport 443 | 155k | 1.1M | bps pkt |
| -p tcp -m tcp –dport 80 (does match) | 140k | 990k | bps pkt |
| -d 10.0.0.$i | 460k | 3.2M | bps pkt |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Different kind of matches have different kind of impact. -d or -s have about the same impact.
other configs
Tests done with 256 -s xxx matches, as it's the one that gave the best performances so far.
| match rules | conn/s | pkt/s | graph |
|---|---|---|---|
| default | 480k | 3.38M | bps pkt |
| ethtool -G eth1 {tx/rx} 512 | 505k | 3.6M | bps pkt |
| ethtool -G eth1 {tx/rx} 64 | 450k | 3.2M | bps pkt |
| ip link set eth1 txqueuelen 10000 | 470k | 3.3M | bps pkt |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
txqueuelen - no effect
ring parameters rx/tx, do have an effect, and neither too big nor too small is the best.
tree search
netfilter allow to use chains, with a few match, you can send to a chain, and avoid doing what is in the chain if it does not match.
As seen previously, having alot of match in a single chain means that the packet is tested for all possible match.
Lets see how we could have per ip match for a whole /13. (yeah, that mean 512k different IPs)
Using iptables to generate that many entry is just too slow, it would take days. generating a result, and using iptables-restore can provide way better performances (5-10 minutes, instead of days).
Having 512k rules to match for each packet would slow down the trafic alot. A way to do it would is to get a few matches, and send to a specific rule. Then match a few more bits, and send to other rules.
Ideas for that Jesper Dangaard Brouer slides about Making large iptables rulesets scale. Unfortunatly, the perl library has not been updated to build with wheezy iptables version yet.
Exemple of rules that would be checked/matched for 10.139.5.43 :
-A FORWARD -s 10.128.0.0/12 -j cidr_12_176160768 (match)
-A cidr_12_176160768 -s 10.136.0.0/14 -j cidr_14_176685056 (match)
-A cidr_14_176685056 -s 10.136.0.0/16 -j cidr_16_176685056
-A cidr_14_176685056 -s 10.137.0.0/16 -j cidr_16_176750592
-A cidr_14_176685056 -s 10.138.0.0/16 -j cidr_16_176816128
-A cidr_14_176685056 -s 10.139.0.0/16 -j cidr_16_176881664 (match)
-A cidr_16_176881664 -s 10.139.0.0/18 -j cidr_18_176881664 (match)
-A cidr_18_176881664 -s 10.139.0.0/20 -j cidr_20_176881664 (match)
-A cidr_20_176881664 -s 10.139.0.0/22 -j cidr_22_176881664
-A cidr_20_176881664 -s 10.139.4.0/22 -j cidr_22_176882688 (match)
-A cidr_22_176882688 -s 10.139.4.0/24 -j cidr_24_176882688
-A cidr_22_176882688 -s 10.139.5.0/24 -j cidr_24_176882944 (match)
-A cidr_24_176882944 -s 10.139.5.0/26 -j cidr_26_176882944 (match)
-A cidr_26_176882944 -s 10.139.5.0/28 -j cidr_28_176882944
-A cidr_26_176882944 -s 10.139.5.16/28 -j cidr_28_176882960
-A cidr_26_176882944 -s 10.139.5.32/28 -j cidr_28_176882976 (match)
-A cidr_28_176882976 -s 10.139.5.32/30 -j cidr_30_176882976
-A cidr_28_176882976 -s 10.139.5.36/30 -j cidr_30_176882980
-A cidr_28_176882976 -s 10.139.5.40/30 -j cidr_30_176882984 (match)
-A cidr_30_176882984 -s 10.139.5.40/32 -j cidr_32_176882984
-A cidr_30_176882984 -s 10.139.5.41/32 -j cidr_32_176882985
-A cidr_30_176882984 -s 10.139.5.42/32 -j cidr_32_176882986
-A cidr_30_176882984 -s 10.139.5.43/32 -j cidr_32_176882987 (match)
-A cidr_32_176882987 ...
-A cidr_28_176882976 -s 10.139.5.44/30 -j cidr_30_176882988
-A cidr_26_176882944 -s 10.139.5.48/28 -j cidr_28_176882992
-A cidr_24_176882944 -s 10.139.5.64/26 -j cidr_26_176883008
-A cidr_24_176882944 -s 10.139.5.128/26 -j cidr_26_176883072
-A cidr_24_176882944 -s 10.139.5.192/26 -j cidr_26_176883136
-A cidr_22_176882688 -s 10.139.6.0/24 -j cidr_24_176883200
-A cidr_22_176882688 -s 10.139.7.0/24 -j cidr_24_176883456
-A cidr_20_176881664 -s 10.139.8.0/22 -j cidr_22_176883712
-A cidr_20_176881664 -s 10.139.12.0/22 -j cidr_22_176884736
-A cidr_18_176881664 -s 10.139.16.0/20 -j cidr_20_176885760
-A cidr_18_176881664 -s 10.139.32.0/20 -j cidr_20_176889856
-A cidr_18_176881664 -s 10.139.48.0/20 -j cidr_20_176893952
-A cidr_16_176881664 -s 10.139.64.0/18 -j cidr_18_176898048
-A cidr_16_176881664 -s 10.139.128.0/18 -j cidr_18_176914432
-A cidr_16_176881664 -s 10.139.192.0/18 -j cidr_18_176930816
-A cidr_12_176160768 -s 10.140.0.0/14 -j cidr_14_176947200
With at most 39 check, and 11 jump, any IP within the /13 arrives it its own chain (or merged chained, if you have serveral IP that need the same rules). Anything not even in the /12 would get just one check, and get to the next entries.
| bits matched per level | check | match | conn/s | pkt/s | graph |
|---|---|---|---|---|---|
| 2 | 39 | 11 | 560k | 3.9M | bps pkt |
| 3 | 51 | 8 | 595k | 4.2M | bps pkt |
| 4 | 73 | 6 | 580k | 4.0M | bps pkt |
| 5 | 113 | 5 | 575k | 4.0M | bps pkt |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note: such high number of rules uses memory. Like 20GB+ of ram used.
nat
Earlier, we already noticed that conntracking all our connections would be too much. What if we can have a main 1:1 mapping that would not require any tracking ?
Well, iptables NOTRACK prevent any form of nat, so that can't be done…
Will have to seek for other solutions.
ipset
Some people mentionned ipset. Lets bench that.
# lets create some sets we might use ipset create ip hash:ip ipset create net hash:net ipset create ip,port hash:ip,port ipset create net,port hash:net,port
Rules used for different tests :
-A FORWARD -m set --match-set ip src -A FORWARD -m set --match-set net src -A FORWARD -m set --match-set net,port src,src -A FORWARD -m set --match-set ip,port src,dst
Lets see how a few match for hash:ip affects our traffic :
| # rules | conn/s | pkt/s |
|---|---|---|
| 1 | 570k | 3.6M |
| 2 | 340k | 2.05M |
| 3 | 240k | 1.45M |
| 4 | 184k | 1.1M |
Ok, so just a few ipset match affects us ALOT. What about other hashes ?
(tests done with 2 matches)
| ipset | conn/s | pkt/s |
|---|---|---|
| hash:ip | 340k | 2.05M |
| hash:net | 350k | 2.1M |
| hash:ip,port | 330k | 2M |
| hash:net,port | 330k | 2M |
Net or ip doesn't change much, and including the port is only a light overhead, considering the overhead we already have.
What about ipset bitmasks ?
ipset create bip0 bitmap:ip range 10.136.0.0-10.136.255.255 ipset create bip1 bitmap:ip range 10.140.0.0-10.140.255.255
| # rules | conn/s | pkt/s |
|---|---|---|
| 2 | 550k | 3.5M |
| 4 | 320k | 1.9M |
Considering ipset is limited to 65k entries, and the results, I would advise against using it, unless you really need the easy to manage set.
interface irq affinity
 : add irq affinity matches with results
: add irq affinity matches with results
Conclusion
- Alot of matching reduce performances.
- u32 are costly
- if you can, try to match and segregate to different subchains, with like 8 to 16 match per chain (for src/dst match, maybe less with heavier match)
- irq affinity can change performances on high loads
